
Systematische Reviews bündeln Studien zu einer bestimmten Fragestellung und unterstützen damit Gesundheitsentscheidungen. Künstliche Intelligenz (KI) kann einzelne Arbeitsschritte beschleunigen. Von einem fertigen Review-Backautomaten sind wir jedoch noch weit entfernt. Damit die Ergebnisse verlässlich bleiben, sind Transparenz und klare Kontrollen notwendig.
Was mit Künstlicher Intelligenz gemeint ist
Der Begriff „KI“ umfasst ein breites Spektrum, von einfachen Automatisierungen bis zu lernenden Verfahren (siehe Grafik). Eine wichtige Untergruppe sind große Sprachmodelle oder englisch Large Language Models (LLMs). Dabei handelt es sich um Programme, die aus vielen Daten gelernt haben und neue Inhalte wie Texte erzeugen können. Seitdem das Unternehmen OpenAI Ende 2022 seinen Chatbot ChatGPT veröffentlicht und einer breiten Nutzerschaft zugänglich gemacht hat, haben große Sprachmodelle rasant an Popularität gewonnen. Ihr Einsatz wird heute in der Forschung diskutiert und erprobt, auch bei der Erstellung systematischer Reviews.
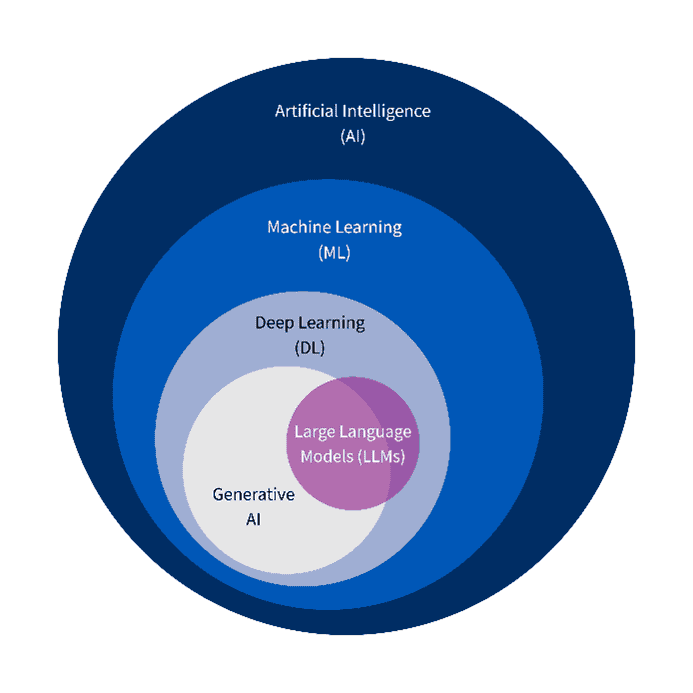
Künstliche Intelligenz (Artificial Intelligence) dient als Oberbegriff für Maschinen, die menschliches Denken imitieren. Das Maschinelle Lernen (Machine Learning) beschreibt Verfahren, bei denen Computer eigenständig aus Daten lernen. Große Sprachmodelle (Large Language Models, LLMs) sind ein Teilbereich und sind auf die Verarbeitung und Erzeugung natürlicher Sprache spezialisiert, zum Beispiel ChatGPT.
KI im Review-Alltag: Wo sie unterstützen kann
Ein systematisches Review läuft in klaren Schritten ab: Zuerst wird die Frage festgelegt, dann werden Studien systematisch gesucht, ausgewählt und gelesen. Danach werden Daten aus den Studien entnommen, das Verzerrungsrisiko bewertet und die Ergebnisse zusammengefasst. Abschließend wird die Vertrauenswürdigkeit der Evidenz mit dem GRADE-Ansatz eingeschätzt („Grading of Recommendations Assessment, Development and Evaluation“).
Insgesamt besteht die Arbeit für ein systematisches Review aus vielen zeitintensiven und sich teilweise wiederholenden Schritten, bei denen viel Text gesichtet werden muss. Hier verspricht der Einsatz von KI großen Nutzen und Zeitersparnis.
Bei der Studienauswahl kann ein Tool beispielsweise die Trefferliste so sortieren, dass wahrscheinlich passende Studien weiter oben stehen. Das spart Zeit und kann vergleichsweise risikoarm sein, solange Menschen weiterhin entscheiden, was tatsächlich eingeschlossen wird. Diese Möglichkeit ist bereits in mancher Software, die die Studienauswahl unterstützt, enthalten. Diskutiert und getestet werden weitere Varianten der KI-gestützten Studienauswahl: Beispielsweise könnte KI-gestützt ein gewisser Anteil an sehr wahrscheinlich nicht relevanten Studien aussortiert werden, ohne dass Menschen sich diese noch einmal anschauen müssen. Oder eine von zwei Personen, die gewöhnlich unabhängig voneinander alle Suchtreffer auf ihre Relevanz hin sichten, wird durch eine KI-Auswahl ersetzt, wobei alle Diskrepanzen zwischen Mensch und KI anschließend überprüft werden müssen. Bevor solche Ansätze praktisch eingesetzt werden, ist es notwendig, sie für die jeweilige Situation und den Themenbereich genau zu testen und sicherzustellen, dass sie zuverlässig funktionieren.
Beim Lesen von Volltexten kann KI helfen, lange Dokumente schneller zu überblicken, etwa indem sie relevante Abschnitte zu Population, Intervention und Endpunkten hervorhebt.
Bei der Datenentnahme kann KI relevante Zahlen und weitere Angaben, beispielsweise zur Population oder Intervention, identifizieren und in eine Vorlage übertragen, die anschließend von Menschen geprüft und wenn nötig korrigiert wird. Auch diese Funktionen werden in mancher Systematic Review Software bereits angeboten. Und wieder gilt: Die Zuverlässigkeit dieser Ansätze muss überprüft werden, bevor sie in der Praxis für systematische Übersichtsarbeiten eingesetzt werden können.
Große Sprachmodelle können nicht nur Text analysieren, sondern auch Texte formulieren. Mit Hilfe von ChatGPT und Co lässt sich schnell ein eloquenter Absatz formulieren. Diese Funktion kann beim Verfassen von Publikationen zu systematischen Übersichtsarbeiten helfen. Beispielsweise können Sprachmodelle genutzt werden, um leicht verständliche Zusammenfassungen von systematischen Übersichtsarbeiten zu formulieren. Natürlich muss jeder KI-generierte Text kritisch auf seine Korrektheit überprüft werden.
KI-Halluzinationen und andere Risiken
Große Sprachmodelle neigen dazu, Dinge sehr überzeugend zu formulieren. Forschende müssen sicherstellen, sich nicht in die Irre führen zu lassen, und die Zuverlässigkeit von KI-generierten Informationen immer kritisch hinterfragen. Die erstellten Inhalte können unpräzise oder falsch sein. Bekannt sind etwa sogenannte Halluzinationen, bei denen das Sprachmodell neue, falsche Inhalte produziert.
Besonders heikel ist in diesem Zusammenhang die Literaturrecherche. Aus Testungen ist bekannt, dass große Sprachmodelle in der Vergangenheit Hinweise auf Studien lieferten, die in Wahrheit gar nicht existierten. Auch bei der Erstellung einer Suchstrategie mithilfe von ChatGPT oder anderen Tools ist Vorsicht geboten. Wenn Suchbegriffe oder Suchlogik unpassend sind, werden relevante Studien nicht gefunden, und dieser Fehler lässt sich später kaum ausgleichen. Anwendungen mit Sprachmodellen in diesem Schritt wurden in einer Übersichtsarbeit zu diesem Thema als noch nicht zuverlässig genug eingeordnet.
Der Goldstandard Mensch
In der Wissenschaft bezeichnet der Goldstandard das Verfahren, das als die verlässlichste verfügbare Methode zur bestmöglichen Annäherung an die Wahrheit gilt. Bei der Erstellung systematischer Reviews ist es üblich, dass mindestens zwei erfahrene Forschende wesentliche Schritte der Review-Erstellung unabhängig voneinander durchführen und Unterschiede systematisch klären.
Dieser Prozess reduziert Fehler, liefert aber keine objektive Wahrheit. Selbst erfahrene Reviewer*innen übersehen Datenpunkte oder ordnen Informationen unterschiedlich ein.
Entscheidend ist nicht nur, ob Fehler passieren, sondern auch wie sie sich verteilen und wie leicht sie zu entdecken sind. Menschliche Fehler sind oft individuell und heterogen. In Teams können sie sich teilweise gegenseitig auffangen, sofern unabhängig gearbeitet und konsequent abgeglichen wird. Bei KI verschiebt sich das Risiko: Ein Tool kann sehr effizient sein, aber es kann auch systematisch dieselben Fehler wiederholen. Wenn ein Modell zum Beispiel bestimmte Angaben regelmäßig übersieht, kann sich dieser Fehler über viele Studien hinweg vervielfachen, ohne aufzufallen.
Leitplanken für verantwortliche Nutzung
Mehrere Organisationen, die systematische Reviews erstellen, darunter Cochrane, haben 2025 ein gemeinsames Positionspapier zur Nutzung von KI veröffentlicht. Zentrale Aussage ist, dass Autor*innen „die fachliche und methodische Verantwortung tragen, auch wenn KI-Tools einzelne Arbeitsschritte unterstützen.“ Die Organisationen haben einen umfangreichen Leitfaden erstellt, auf den sie in ihrem Positionspapier verweisen: RAISE -„Responsible use of AI in evidence SynthEsis“. RAISE steht für eine verantwortungsvolle KI-Nutzung entlang des gesamten Review-Prozesses und über alle Beteiligten hinweg, also Autor*innen, Methodenexpert*innen, Herausgeber*innen und Tool-Anbieter. Ziel ist, dass KI-Nutzen ermöglicht wird, ohne Kernprinzipien evidenzbasierter Arbeit zu gefährden, insbesondere methodische Strenge, Transparenz, Reproduzierbarkeit und klare Zuständigkeiten.
Das Positionspapier benennt konkrete Risikotypen:
- „Black-Box“-Entscheidungen: wenn ein Tool Ergebnisse liefert, ohne nachvollziehbar zu machen, wie es zu ihnen kommt;
- systematische Verzerrungen (Bias): wenn Trainingsdaten oder Modelllogik bestimmte Studien, Populationen oder Resultate bevorzugen;
- erfundene oder falsch abgeleitete Inhalte: wenn eine Ausgabe plausibel klingt, aber nicht durch die eingeschlossenen Studien gedeckt ist.
Deshalb wird die Überprüfung und Kontrolle durch Menschen besonders dort gefordert, wo KI Urteile nahelegt oder Entscheidungen unterstützt, etwa bei Ein- und Ausschlüssen von Studien, der Entnahme von Ergebnisdaten oder der Bewertung der Vertrauenswürdigkeit der Evidenz.
Transparenz ist kein Selbstzweck, sondern Voraussetzung für Vertrauen. Für Leser*innen sollte klar erkennbar sein, in welchen Review-Schritten KI genutzt wurde, ob sie Entscheidungen beeinflusst hat und wie Menschen die Ergebnisse geprüft haben. Wenn diese Informationen fehlen, lassen sich Verlässlichkeit und Übertragbarkeit der Evidenz nicht einordnen.
Cochrane und Künstliche Intelligenz
Cochrane hat Ende 2025 einen Aufruf gestartet, Vorschläge für KI-Tools einzureichen, die einzelne Arbeitsschritte bei der Erstellung von Cochrane Reviews unterstützen könnten. Bevor solche Tools Autor*innen breit empfohlen werden, sollen sie in einem Pilotprogramm systematisch getestet und bewertet werden. Ziel ist, praxistaugliche Werkzeuge gemeinsam mit Anbietenden so weiterzuentwickeln, dass sie methodisch robust sind und sich an verantwortungsvolle Nutzungsempfehlungen wie RAISE anlehnen.
Sinnvoll nutzen, Qualität sichern
Im Internet gibt es bereits „Review-Backautomaten“, die in kurzer Zeit Übersichtsarbeiten ausgeben. Wenn dabei Transparenz, klare Kontrollen und unabhängige Prüfung fehlen, vereint das die oben beschriebenen Risiken: mögliche Lücken in der Suche, Fehlentscheidungen bei der Auswahl und schwer erkennbare Fehler in Daten und Bewertung, im schlimmsten Fall ergänzt durch Halluzinationen.
KI kann die Erstellung von systematischen Reviews sinnvoll unterstützen, derzeit vor allem beim Priorisieren großer Trefferlisten und beim Vorbereiten strukturierter Datenvorlagen. Gleichzeitig steigt das Risiko systematischer Fehler, wenn KI-Informationen nicht konsequent gegengeprüft und nachvollziehbar dokumentiert werden. Besonders bei Schritten mit hohem Einfluss auf Ergebnisse bleibt unabhängige menschliche Kontrolle unverzichtbar. Cochrane und Partnerorganisationen fordern deshalb verantwortungsvolle Nutzung nach RAISE und transparente Berichterstattung, damit Evidenz auch mit KI-Unterstützung prüfbar bleibt.
Ein wirklich zuverlässiger Review-Backautomat bleibt damit noch Zukunftsmusik.
Quellen
- Deep Learning – Das umfassende Handbuch: Grundlagen, aktuelle Verfahren und Algorithmen, neue Forschungsansätze“ (EAN/ISBN: 9783958457003)
- Viet-Thi Tran, Gerald Gartlehner, Sally Yaacoub, et al. Sensitivity and Specificity of Using GPT-3.5 Turbo Models for Title and Abstract Screening in Systematic Reviews and Meta-analyses. Ann Intern Med.2024;177:791-799. [Epub 21 May 2024]. doi:10.7326/M23-3389
- LASER AI: Accelerate Evidence Synthesis with Secure AI
- Ovelman C, Kugley S, Gartlehner G, Viswanathan M. The use of a large language model to create plain language summaries of evidence reviews in healthcare: a feasibility study. Cochrane Ev Synth. 2024; 2:e12041. doi:10.1002/cesm.12041
- The role of ChatGPT in developing systematic literature searches: an evidence summary . J Eur Assoc Health Info Libr [Internet]. 2024 Jun. 27 [cited 2026 Feb. 16];20(2):30-4. Available from: https://ojs.eahil.eu/JEAHIL/article/view/623 ; Parisi and Sutton
- Recommendations and guidance on responsible AI in evidence synthesis | Cochrane
- Lesley Uttley, Daniel S. Quintana, Paul Montgomery, Christopher Carroll, Matthew J. Page, Louise Falzon, Anthea Sutton, David Moher, The problems with systematic reviews: a living systematic review, Journal of Clinical Epidemiology, Volume 156, 2023, Pages 30-41, ISSN 0895-4356, https://doi.org/10.1016/j.jclinepi.2023.01.011.
Autorinnen: Dr. Angelika Eisele-Metzger & Dr. Alicia Zink
Diese Artikel könnten Sie auch interessieren:

