
Ein systematischer Review zu Behandlungen zielt normalerweise darauf ab, die folgende Frage zu beantworten: Was ist die Wirkung von Behandlung A im Vergleich zu Behandlung B? Doch auch ein systematischer Review kann diese Frage nicht immer beantworten.
Dies ist der 30. Beitrag aus einer Blogserie zu „Schlüsselkonzepten zur besseren Bewertung von Aussagen zu Behandlungen“, die im Rahmen des Projektes Informed Health Choices erarbeitet wurden. Jeder der insgesamt 36 Blogbeiträge befasst sich mit einem Schlüsselkonzept, das dabei hilft, Aussagen zu Wirkungen von Behandlungen besser verstehen und einordnen zu können.
Evidenz versus Wirksamkeit
Ein systematischer Review – also eine analytische Synthese aller vorhandener Evidenz zu einer medizinischen Fragestellung – kann die Frage, welche von zwei Behandlungen – A oder B – besser ist, oft nicht klar beantworten. Die Studien, auf denen die Evidenz eines Reviews basiert, liefern natürlich Informationen zu den Wirkungen der beiden im Review untersuchten Behandlungen oder Interventionen, und ziehen einen Vergleich. Wenn jedoch keine ausreichende Evidenz zur Verfügung steht, können wir nicht beurteilen, ob die Behandlungen sich unterscheiden.
Bei der Interpretation der Ergebnisse von systematischen Reviews (und von anderen Studien) ist deshalb immer wichtig, dass wir „keine Evidenz für einen Unterschied“ nicht mit „Evidenz für keinen Unterschied“ verwechseln.
Wo liegt das Problem?
Das Problem: Wenn es keinen statistisch signifikanten Unterschied zwischen Behandlung A und Behandlung B gibt, nimmt man mitunter fälschlicherweise an, dass dies zwangsläufig bedeutet, dass die beiden Interventionen gleichwertig sind. Selbst wenn kein statistisch signifikanter Unterschied besteht, ist es dennoch möglich, dass es einen klinisch relevanten Unterschied gibt. Es könnte sein, dass die eine Behandlung in Wirklichkeit besser als die andere ist, der Unterschied sich jedoch nicht statistisch signifikant belegen lässt, da die Anzahl der Ergebniswerte zu gering ist, um eine „statistische Signifikanz“ zu ermitteln.
Wie kann ich dieses Problem umgehen?
Die beste Methode, dieses Problem zu vermeiden, ist, das Konfidenzintervall zu betrachten (Mehr zur Thematik „Konfidenzintervall in diesem Artikel. Wenn das 95 %- Konfidenzintervall sowohl eine klinisch relevante Wirkung als auch keine Wirkung umfasst, legt dies nahe, dass wir nicht wissen, ob die Behandlung wirksam ist oder nicht, da keine ausreichende Evidenz vorliegt.
Wann liegt „keine Evidenz für einen Unterschied“ vor?
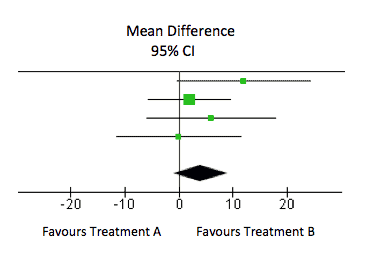
In diesem Forest Plot ist das Gesamtergebnis (durch die Raute dargestellt) ein durchschnittlicher Unterschied von 4,02 (95 %-Konfidenzintervall: -1,06 bis 9,11). Dieser Unterschied ist statistisch nicht signifikant (das Konfidenzintervall überschreitet die 0). Dies bedeutet jedoch nicht, dass es in Wirklichkeit keine Wirkung gibt. Nehmen wir einmal an, die Grenze für einen klinisch bedeutsamen Unterschied bei diesem Ergebnis würde bei 8 Punkten liegen. Das 95 %-Konfidenzintervall schließt die 8 ein, sodass das Ergebnis nahelegt, dass wir nicht sicher sein können, dass es nicht doch einen klinisch relevanten Unterschied gibt. Der Grund hierfür ist in aller Regel, dass zu wenige Ergebniswerte für die Behandlungen vorliegen, d. h. die Studie keine ausreichende „Power“ hat (d. h. underpowered ist).
Wann liegt „Evidenz für keine Differenz“ vor?
Wenn das Ergebnis jedoch nahe 0 (bzw. nahe dem Wert für keinen Unterschied) ist und das Konfidenzintervall eng ist, legt dies nahe, dass es tatsächlich keine oder zumindest keine relevante Wirkung gibt. Im nachstehenden Forest Plot ist das Gesamtergebnis ein durchschnittlicher Unterschied von 1,81 (95 %-Konfidenzintervall: -2,95 bis 6,57). Dieses schließt die 8 (unsere angenommene Schwelle für eine relevante Wirkung) nicht ein und legt daher nahe, dass es keinen klinisch bedeutsamen Unterschied gibt.
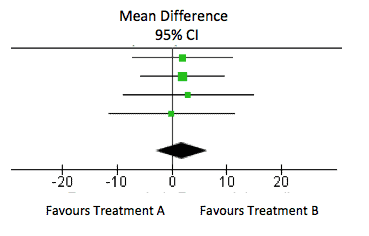
Um weitere Evidenz dafür zu bekommen, dass zwei Behandlungen gleichermaßen wirksam sind, könnten wir uns dafür entscheiden, eine Nicht-Unterlegenheitsstudie oder Äquivalenzstudie zu verwenden, um zu ermitteln, ob eine nützliche Behandlungswirkung sicher ausgeschlossen werden kann.
Wieso liegt keine Evidenz vor?
„Keine Evidenz“ bedeutet nicht immer, dass keine Studien zur Behandlung vorliegen. Manchmal bedeutet es einfach nur, dass zu wenig Daten vorliegen, oder nicht ausreichend viele Studien, um aussagekräftige Schlussfolgerungen zur Behandlungswirkung zu rechtfertigen. Entsprechend ist es möglich, dass es eine Reihe von Studien gibt, dass aber, wenn diese ziemlich klein sind, immer noch nicht ausreichend viele Ergebniswerte vorliegen, um abzuschätzen, ob eine Wirkung besteht. Wenn die Studie also einen binären Endpunkt hat (z. B. ist die Person gestürzt oder nicht?), liegt möglicherweise nur wenig Evidenz vor, da nicht ausreichend Ergebnisereignisse vorliegen (z. B. wenn nur sehr wenige Personen gestürzt sind).
Selbst wenn einige der eingeschlossenen Studien größere Stichprobengrößen haben, können andere Gründe dafür vorliegen, weshalb ein Review zu dem Schluss kommt, dass nicht ausreichend Evidenz vorliegt. Ein Review kann zum Beispiel zu dem Schluss kommen, dass „unzureichende Evidenz“ vorliegt, wenn die Evidenz von niedriger Vertrauenswürdigkeit ist – weil:
- die eingeschlossenen Studien von niedriger Vertrauenswürdigkeit waren, denn wenn es keine Studien von hoher Vertrauenswürdigkeit gab, können wir von ihren Ergebnissen nicht ausreichend überzeugt sein.
- es nur indirekte Evidenz gibt – z. B. wenn in einen Review über die Wirkung eines Blutdruck-Medikaments nur Raucher eingeschlossen werden, könnte man davon ausgehen, dass dies keine ausreichende Evidenz für die Beantwortung der Frage ist, ob das Medikament bei Nichtrauchern wirksam ist.
- eine große statistische Heterogenität vorhanden ist – die Ergebnisse der Studien stimmen nicht überein (z. B. wenn es in einigen Studien große Wirkungen gibt, in anderen jedoch nur geringere Wirkungen)
Zusammengefasst heißt das: - Wenn ein Ergebnis statistisch nicht signifikant ist, bedeutet das nicht automatisch, dass die Behandlung wirkungslos ist
- Betrachten Sie das Konfidenzintervall, um festzustellen, ob es eine klinisch bedeutsame Wirkung einschließt
- Betrachten Sie die Qualität der Evidenz ebenso wie das zusammengefasste Ergebnis.
Text: Bethan Copsey
Übersetzt von: Brita Fiess

Mit dem Laden des Videos akzeptieren Sie die Datenschutzerklärung von YouTube.
Mehr erfahren
Für weitere Informationen lesen Sie: Altman, D. G., & Bland, J. M. (1995). Statistics notes: Absence of evidence is not evidence of absence. Bmj, 311(7003), 485.
Anmerkung: Aus Gründen der besseren Lesbarkeit wird auf die gleichzeitige Verwendung männlicher und weiblicher Sprachformen verzichtet. Sämtliche Personenbezeichnungen gelten gleichermaßen für alle Geschlechter.
Diese Artikel könnten Sie auch interessieren:


